Apr 21, 2026
Retrieval vs. Reasoning: Where Linkup and GPT fit in your AI stack
We don’t just return an “answer” but a detailed, sourced web context that your AI systems can reason over.

Boris
COO at Linkup
Search APIs like Linkup and answer engines like OpenAI operate at distinct layers of the AI stack. Modern systems increasingly combine both, but performance depends on correctly identifying when the bottleneck is retrieval versus reasoning and applying each layer accordingly.
Two layers, different responsibilities
Linkup operates as the retrieval layer. It fetches real-time, structured data from the web. Instead of returning a single generated answer, it returns traceable information snippets, each tied to a specific source URL. Linkup operates early in the pipeline. Its role is to ensure that downstream systems, typically language models, have access to current, high-quality data inputs.
GPT (OpenAI) operates as the reasoning layer. It takes input and produces fluent, structured responses. Its strength lies in reasoning and communication, synthesizing information into something coherent and useful. However, it does not natively retrieve fresh information. Its knowledge is bounded by training data unless augmented with external retrieval.
These systems are not substitutes for one another. Increasingly, production systems require both.
When to use each tool

When reasoning is the bottleneck
GPT is sufficient when external, real-time data is not critical. If the task is to draft an email, summarize internal documents, or help write code, the value lies primarily in how the answer is produced, not in whether it reflects the latest information from the web.
In these scenarios:
The knowledge required is relatively stable
Output quality depends on reasoning and phrasing
Freshness is not a hard constraint
In these cases, GPT delivers strong results while being easy to integrate, even for teams without deep technical expertise, and requires minimal infrastructure. Adding a retrieval layer may introduce latency and complexity without materially improving outcomes.
When retrieval is the bottleneck
When a system's correctness depends on up-to-date information, a language model's knowledge – frozen at training time – is not sufficient. This gap is particularly consequential in research-intensive and time-sensitive workflows.
Consider a system analyzing financial markets. It may need to process the latest earnings calls, company announcements, or regulatory filings. In enterprise settings, outdated or unverifiable information is not just inconvenient, it can have long-standing operational and reputation implications.
Linkup is designed for these conditions. It provides:
Real-time access to web data
Explicit source attribution
Structured outputs suitable for downstream processing
The result is a system that can be audited, controlled, and integrated into production pipelines.
GPT has web search. Why isn't that enough?

For lightweight use cases, GPT’s web search can be sufficient. But for production systems, the limitations become visible quickly.
ChatGPT's web search returns a “black box answer.” Users see a generated summary with no visibility of the underlying data. You don’t know what the model specifically consulted – whether that was the full page, or just a select snippet. GPT also offers limited control over sources, filtering, and output structure. In production environments, particularly those that require reliability or auditability, these limitations become more visible.
A dedicated retrieval system like Linkup provides clearer sourcing and outputs that can be directly integrated into downstream pipelines. Every result is traceable to a specific URL. Output formats and retrieval depth are configurable. Domains can be whitelisted or blacklisted on demand.
On a blind, LLM-as-a-judge benchmark with leading search providers, Linkup showed 2-3x more source diversity, the lowest hallucination rates, and the highest completeness on complex, multi-hop queries. Read more and try the open source benchmark here.
Using Both Together
The most capable production systems combine retrieval and reasoning deliberately. The standard pattern is to call Linkup upstream of a language model. A user submits a query; Linkup retrieves the most relevant, current documents from the web; those documents are injected into the prompt context; OpenAI or another model reasons and generates a coherent response.
Pricing differences
OpenAI charges by token – including both input and output. Costs scale with the complexity and volume of generation. A high-reasoning workload with long contexts will accumulate costs primarily here.
Linkup charges by query and retrieval depth. Costs scale with how frequently the system fetches live web data and how deeply it searches.
Thus, when evaluating budgets, teams should consider if the bottleneck lies in reasoning or in data sourcing. The answer determines where costs will land, and which tool warrants the greater investment.
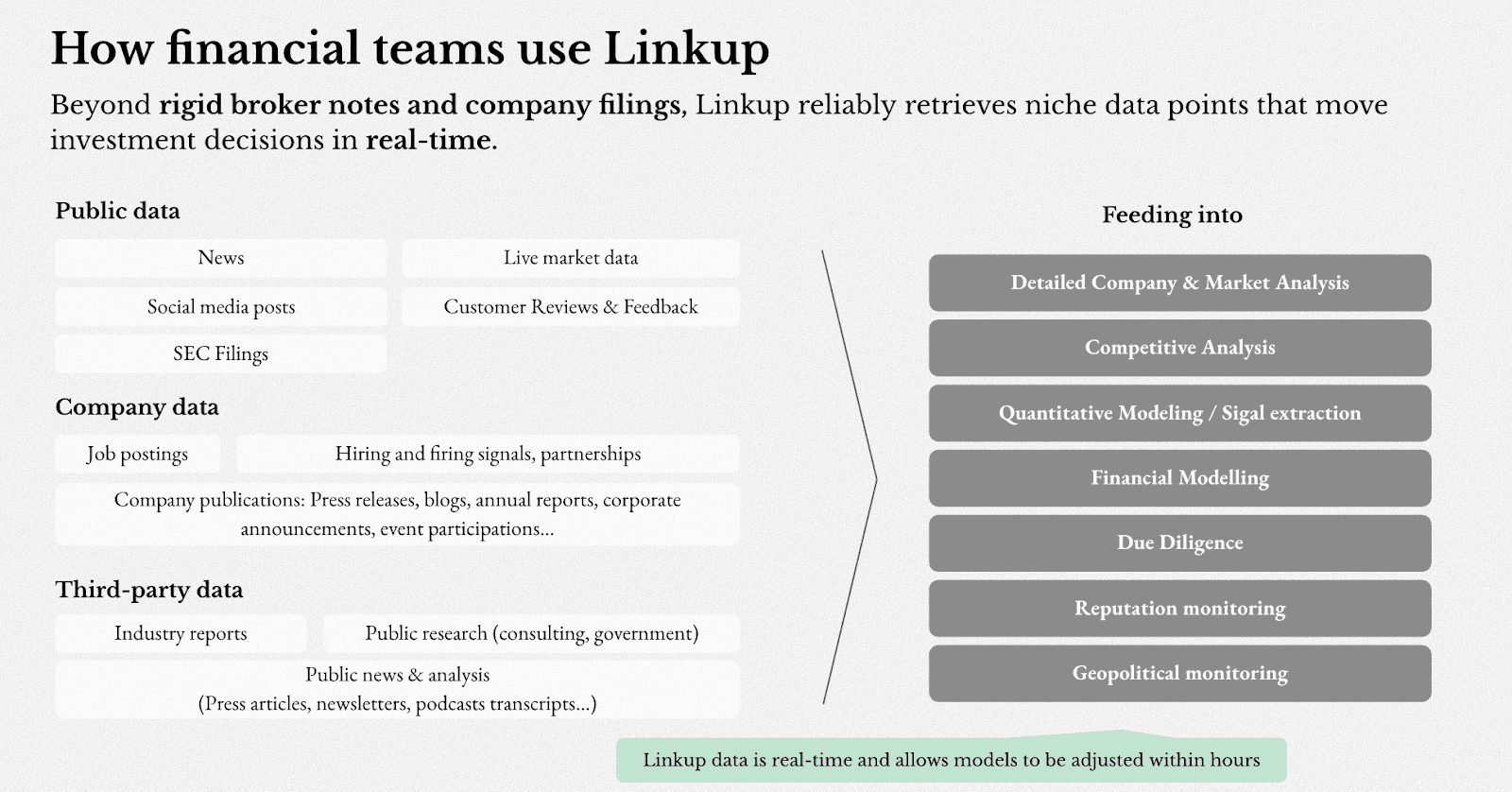
User story: Financial platforms
We ran 30 real-world due diligence queries across two companies to compare how GPT and Linkup handle research-intensive workflows. The pattern was consistent.
When asked about a compliance platform's alignment with 21 CFR Part 11, GPT returned: "For specific compliance details, I recommend consulting the company directly." (0 sources). Linkup retrieved 12 sources covering audit trails, electronic signatures, and secure document management.
When asked about a company's security certifications for enterprise and financial services use, GPT missed key certifications entirely. Linkup returned SOC 2 Type II, ISO 27001, FedRAMP, PCI DSS, and TISAX — each sourced.
When asked to define a proprietary platform name and explain its integrations, GPT returned the wrong acronym definition. Linkup returned the correct terminology with detailed integration capabilities across relevant stakeholders.
Across 30 queries, Linkup averaged ~15 sources per answer versus ~2 for GPT. The gap wasn't in reasoning quality — it was in whether the underlying information existed in the context at all.
This is the core use case for a dedicated retrieval layer: workflows where correctness depends on current, verifiable, external data rather than what a model internalized at training time.
Read more about how we helped one AI investment app report +77% returns in 2025 (4.7× the S&P 500) here.
Conclusion
OpenAI and Linkup solve different problems at different layers of the stack.
Linkup ensures access to current, structured, and verifiable data
OpenAI ensures that data is transformed into useful outputs
The key design decision is not which to use, but how to compose them. As AI systems mature, separating retrieval from reasoning – and connecting them effectively is becoming a standard structural pattern.
To learn more about how to leverage Linkup’s web search in your AI stack, try it for free or learn more from our team here.



