Evaluating AI search systems on complex queries

Linkup Technical Staff
Source diversity, hallucinations, entity coverage: we benchmarked AI search APIs on Linkup user's queries
Abstract
We benchmarked four AI search APIs (Exa, Tavily, Perplexity, and Linkup) on a 600-query dataset drawn from real user traffic, covering various topics including business intelligence, regulatory compliance and multi-entity research tasks. All systems were evaluated under standard API configurations using blind LLM-as-a-judge scoring across three dimensions: source diversity, faithfulness, and entity coverage. Evaluation code is released as open source.Under matched conditions, Linkup showed 2–3× higher source diversity, 2–3× lower missing-entity rates, and the lowest hallucination rates among all providers tested with larger gaps on multi-hop and multi-entity queries. We describe our methodology, limitations, and practical implications below.
Study Motivation
Performance benchmarks for AI search APIs are often built around selective demonstrations making it difficult to draw reliable conclusions across providers.
Our intent with this benchmark was different. We wanted to understand why our users choose Linkup, and to measure performance on dimensions that reflect how enterprise teams actually evaluate a search API in practice. To do this, we ran a controlled evaluation of four widely used AI search APIs — Exa, Tavily, Perplexity, and Linkup — on an identical query set, under identical conditions, scored by a blind LLM-as-a-judge framework. We focused on three properties we found to consistently correlate with downstream task success in enterprise deployments.
- Source diversity. The number of unique domains retrieved per query. Higher diversity reduces dependence on any single source and increases the likelihood of surfacing heterogeneous, cross-jurisdictional information.
- Faithfulness. The share of atomic claims in a response that are grounded in cited sources. This directly targets hallucination risk, a particularly high-stakes failure mode in compliance, due diligence, and decision-support workflows.
- Entity and sub-intent coverage. Whether all key entities and requested components are addressed in a single response. This approximates one-pass completeness, reducing the need for follow-up queries and manual gap-filling.
Evaluation Protocol
To test all systems under identical conditions, we:
- Built a 600-query benchmark designed to reflect real-world enterprise search behavior. (i) 150 queries were sourced from real, anonymized user traffic to represent authentic enterprise workflows. (ii) 450 queries were synthetically generated to systematically expand coverage of scenario difficulties – such as multi-step research tasks, edge cases, and long-tail enterprise needs.
- Prompted all AI search providers using identical prompts and the standard/default API tier access.
- Blindly evaluated outputs using LLM judges and a multi-layered, objective scoring framework using standard NLP evaluation techniques. The evaluation code is released as open source at the end of this benchmark to ensure reproducibility and transparency of results.
- Aggregated results to compare performance across depth, reliability, and completeness.
Note. This evaluation was conducted using the standard API tier of all platforms. Performance of Linkup's /fast endpoint is covered separately in our recent blog post.
Results
1. Source Diversity
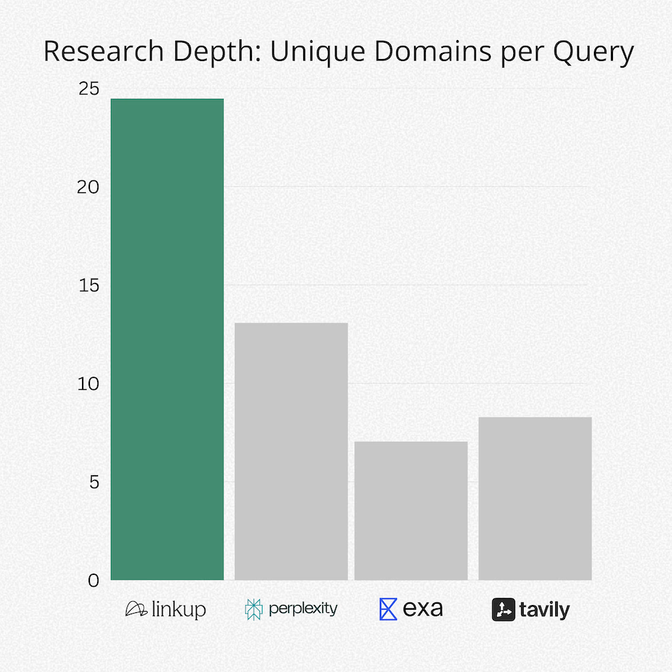
Across the dataset, Linkup retrieved up to 3× more unique domains per query than other systems. Competitors typically returned fewer domains per query, with more overlap across media families.
Higher domain diversity increases the likelihood of capturing heterogeneous viewpoints and reduces dependence on any single source. However, domain count alone does not guarantee higher correctness or source quality.
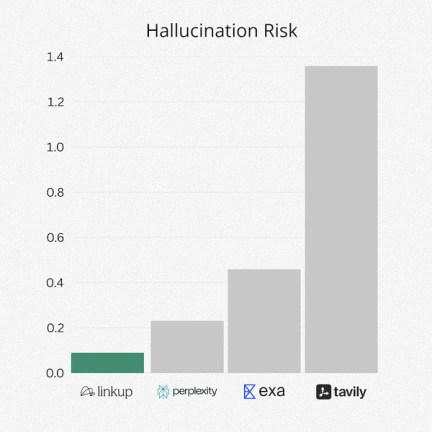
2. Hallucination Rates
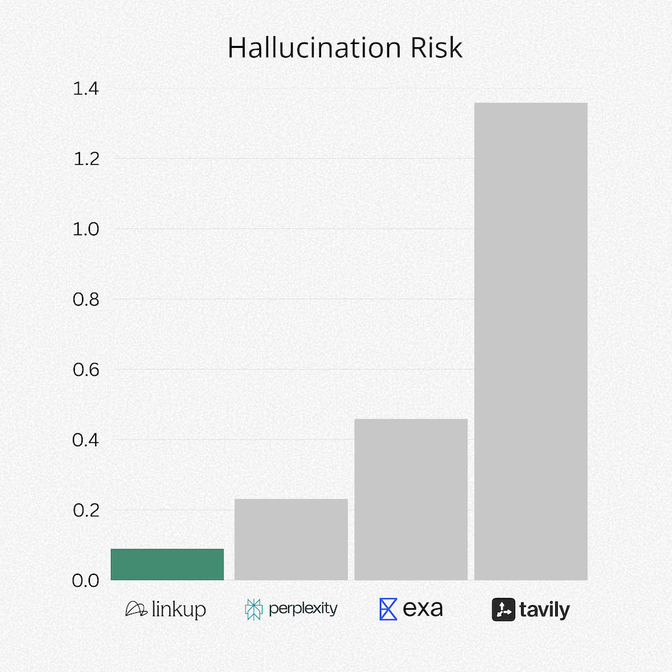
Faithfulness has an inverse relationship with hallucination risk. Thus, a lower hallucination risk depicted above means stronger grounding in cited sources and fewer unsupported claims.
Faithfulness is computed using a claim-level procedure inspired by the RAGAS framework: the judge decomposes each response into atomic statements and checks each claim against the cited source snippets (supported vs. unsupported).
3. Completeness of Answers
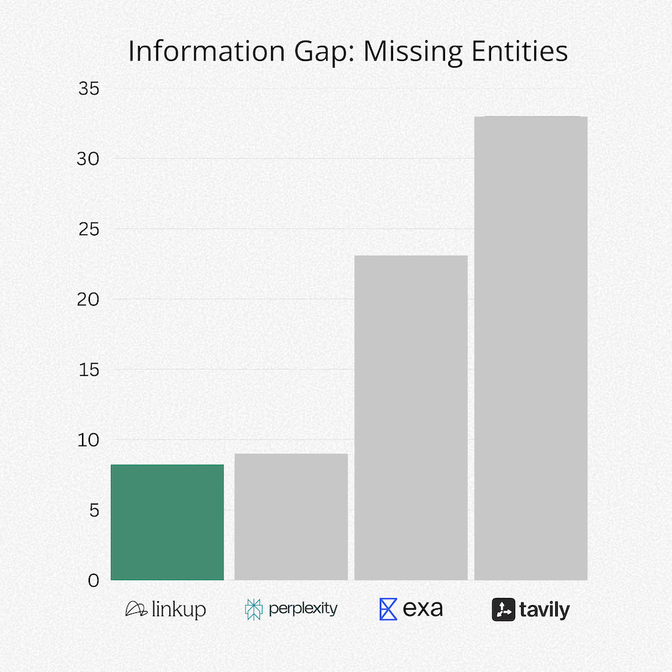
In this benchmark, Linkup showed roughly up to 4× lower missing-entity rates relative to other providers. Entity coverage measures whether key entities and all requested sub queries are addressed. Lower missing-entity rates indicate better sub-intent coverage, which reduces the need for follow-up queries.
These metrics do not fully capture usability factors such as latency, UI experience, or writing coherence; we focus on reliability and completeness due to the high stakes of enterprise needs and decision making.
Methodology
Procedure and Fairness
To ensure objectivity and comparability across providers, we designed a multi-layered evaluation framework created from best practices in NLP (natural language processing) research. We applied the following controls:
- Identical queries and prompting. Every platform was evaluated using the exact same set of 600 benchmark queries, with no rewording, manual cleanup, or query optimization for any individual provider.
- Blind LLM-as-a-judge. To avoid human bias, outputs were assessed using a blinded LLM-as-judge setup (GPT-4o-mini), where the judge did not know which provider produced each response.
- Standard search mode. All providers were evaluated in their standard/default API configurations (i.e., without premium tiers or enhanced search modes).
- Multi-layered scoring framework. No single metric determines performance. Rather, complementary metrics are used and weighted to prioritize grounding and accuracy more than fluency, reflecting the priorities of enterprise research and decision-support use cases.
Query dataset
To reflect real enterprise usage, we evaluated all systems on a benchmark dataset of 600 queries designed to ask the types of questions teams rely on AI search for. We began by sampling 150 seed queries from anonymized, real user traffic to Linkup’s search API. These seed queries capture the natural diversity of how users phrase questions in practice.
From this seed set, we generated an additional 450 synthetic queries derived from the original prompts. These synthetic queries were intentionally constructed to stress-test edge cases that commonly break AI search systems such as:
- Multi-hop reasoning (requiring multiple sources or steps to reach an answer)
- Requests for difficult-to-locate data
- Queries requiring broader coverage across multiple entities, jurisdictions, or timeframes
This ensured difficulty coverage and reduced the chance that any platform would be advantaged by a narrow query set. Together, these queries ensure the benchmark captures both authentic user behavior and hard-but-realistic evaluation conditions, enabling a more rigorous comparison across providers. Further, they span relevant business categories such as business intelligence and people profiles to reflect real-world enterprise needs.
Attribute
Description
Total Size
600 queries
“Seed” Queries
150 “seed” queries were sampled from anonymized, real user traffic to Linkup’s search API.
Synthetic Queries
450 additional synthetic queries generated from the seed set to stress-test edge cases (e.g., multi-hop reasoning, requests for obscure data)
Content Focus
Business intelligence, people profiles, breaking news, regulatory & compliance and broader B2B research workflows.
Scoring Framework
Each response was evaluated across Depth, Reliability, and Completeness. We combined standard NLP evaluation techniques (LLM-as-a-judge, faithfulness scoring, and BERTScore) with enterprise-specific diagnostics that measure source diversity, entity coverage, and one-pass completeness.
Scores are normalized to a 1–10 scale and aggregated using weighted averages that prioritize factual accuracy and completeness over stylistic fluency, reflecting real-world enterprise needs. The table below summarizes the judge types, metrics, and weighting system used.
Scoring System
Judge Type
Key Metrics Evaluated and Weights
Ragas
LLM-as-a-Judge (GPT-4o-mini)
- Faithfulness (45%): Are claims grounded in cited sources?
- Completeness (45%): Does the answer address the full question?
- Source quality (10%): Are sources credible and relevant?
HuggingFace Judges
LLM-as-a-Judge (GPT-4o-mini)
- Factual Correctness (90%): PollMultihop: Binary reasoning check.
- Response Quality (10%): Clarity and usefulness check.
- Prometheus: 1-5 accuracy grade.(Weighted heavily to ensure Reliability)
Automated Metrics
Statistical NLP
- BERTScore Relevance (55%): Topic adherence.
- BERTScore Faithfulness (45%): Citation grounding.
- Diagnostic Indicators (Non-Scored): (i) Entity Coverage, i.e., % of key terms found (Completeness). and (ii) Unique Domains i.e., Research breadth (Depth).
Faithfulness Scoring
Because hallucinations represent one of the highest risks in enterprise AI deployments, Faithfulness serves as a core metric. It is computed as follows:
- Statement Extraction. The LLM judge breaks down the response into atomic, verifiable claims.
- Verdict Assignment. Each claim is checked against the retrieved source snippets.
- 1 = supported by evidence
- 0 = unsupported (hallucinated)
- Score Aggregation.
- Faithfulness = (# Supported Claims) / (Total # Claims), scaled to a 1-10 score
This approach allows us to identify not just whether an answer is right or wrong, but to precisely pinpoint where hallucinations occur in a response. It is inspired by the Ragas framework and is particularly well-suited for enterprise use cases where partial correctness is insufficient.
Limitations
Complex-query emphasis. The benchmark intentionally includes multi-hop, multi-entity, and compliance-style queries, reflecting observed enterprise research workflows. Linkup’s retrieval and ranking pipeline is explicitly optimized for these complex information needs. As a result, this may favor systems optimized for high-recall, complex research, and may under-represent scenarios where lightweight retrieval optimized for simple, single-fact queries is sufficient.
Standard tier only. All providers were evaluated at their standard (lowest-cost) API tier. Some competitors offer premium tiers with enhanced retrieval, deeper search, or higher source limits at increased cost. These premium endpoints were not evaluated. It is possible that competitor performance on complex queries improves at higher price points. This benchmark measures cost-equivalent performance, not maximum capability.
Synthetic query bias. Synthetic queries were generated based on generalizations about difficulty in real-world enterprise searches. Performance may differ if query complexities are geared towards different levels or use cases.
LLM-as-judge limitations. GPT-4o-mini judgments may contain systematic biases. Blind evaluation mitigates but does not eliminate this concern.
Point-in-time evaluation. Provider updates since running this evaluation may change relative performance.
Self-evaluation. This benchmark was conducted by Linkup. We release methodology details and open source evaluation code to enable independent replication.
Practical Implications
Measurable, reproducible reliability creates confidence that AI search can safely support high-stakes professional workflows.
- A finance team can trust that every number in a due diligence brief is source-backed – reducing risk of incorrect valuation assumptions, missed liabilities, or credibility loss in investor-facing documents.
- A compliance team can track changes across local and international regulations with broader coverage, reducing blind spots caused by narrow sources, incomplete summaries, or region-specific guidance being ignored.
- A research lead can receive a synthesized answer that cites both English and Portuguese sources when studying new regulations in Portugal. Other providers often surface only English-language summaries or miss region‑specific guidance entirely, forcing local teams to manually cross-check non‑English sources and slow research cycles.
Note on Data Privacy: The underlying user queries are proprietary and are not published. The benchmark evaluates system performance, not query content.
Conclusion
We evaluated four AI search APIs, Exa, Tavily, Perplexity, and Linkup, on a benchmark designed to reflect real enterprise research workflows. Under matched prompting conditions and standard-tier configurations, Linkup demonstrated consistent advantages across retrieval breadth, citation grounding, and entity coverage.
These results should be read in light of the dataset design and the limitations described above, particularly the emphasis on complex, multi-entity queries. We release the full methodology and evaluation code to support independent replication. Relative performance will evolve as providers update their systems, and we intend to re-run this benchmark periodically.
—
Ready to see how Linkup performs on your queries? Get Started or Talk to our team
—
Sample Queries
The following queries are drawn directly from the 600-query dataset used in this evaluation. They illustrate the range of business intelligence or and multi-entity research tasks covered by the benchmark.
- List of food and beverage companies in the Philippines
- Conduct targeted research on the following company: "Grandvalira", and identify its main activities.
- Challenges of integrating physiotherapy clinics into insurance networks
- Global logistics trends in rail freight: sustainability and partnerships 2024
- I am looking for an analysis of the latest developments in cryptocurrency regulation across major markets, specifically focusing on the United States, Europe, and Asia. The goal is to understand the different regulatory approaches being adopted, notable case law or enforcement actions taken in the past year, and how these regulations are impacting market participants and the overall industry landscape.
- Analysis of sustainable consumption trends in 2023
- I'm conducting an in-depth analysis of lead generation strategies utilized by small to medium-sized enterprises (SMEs) across various industries in 2023. Specifically, I need to compare the effectiveness of social media advertising, email marketing, and content marketing in generating qualified leads. Please include data on conversion rates, cost per lead, and any emerging trends or tools that SMEs are adopting this year.
- Challenges of integrating third-party vendors in cloud security
- How should companies prepare for an audit by the Department of Labor (DOL) regarding wage and hour compliance?
- I am investigating the effectiveness of various employee training and development programs implemented by leading corporations in the pharmaceutical industry over the past year. Specifically, I would like a comparative analysis of different approaches to continuous professional development and their measurable impacts on employee performance and satisfaction.
- How to measure the effectiveness of security training programs
- Latest sustainability initiatives by Fortune 500 companies
- Recent regulatory changes affecting the pharmaceutical industry
- Future of NFT marketplaces after recent market shifts
- I'm conducting an in-depth analysis of current trends in decentralized exchange (DEX) trading volumes, focusing on top platforms like Uniswap, SushiSwap, and PancakeSwap. I'd like to explore how trading volumes have evolved over the last year, particularly in response to recent market fluctuations and the introduction of new liquidity incentives.
- Significant risks associated with cloud migration for enterprises
- Corporate waste reduction obligations: a comparison across major economies
- Explore the latest employee engagement strategies at a leading global food services company.
- Impact of AI on risk management strategies in financial services
- I'm conducting research on the role of social media in recruitment strategies utilized by large firms in 2023. I need insights into how companies leverage platforms like LinkedIn, Facebook, and Twitter to attract potential candidates, including any emerging trends or innovative tactics they have adopted recently.
- Global air cargo operations: market trends and outlook 2024
- Impact of regulatory changes on crypto market volatility
- Recent changes in labor laws affecting remote work across Europe
- Comparison of environmental regulations across major economies
- Recent security breaches in DeFi and their implications


