Mar 24, 2026
Your Open-Source Model's Knowledge Is Already Stale (how to fix it with Baseten + Linkup)

Linkup
Open-source models are flying in airplane mode, Baseten and Linkup turn it off.
These models can reason, write, and orchestrate complex tool calls: they've caught up to proprietary alternatives on most benchmarks that matter. But their knowledge is frozen at training time. Ask one what happened yesterday, and it has nothing to return.
For most production use cases, one hallucination could completely erode the trust of your customers, especially in mission-critical industries. Users expect answers grounded in current content: recent filings, live market data, this morning's news.
That's the problem we partnered with Baseten to solve. Baseten handles model serving and inference at scale. Linkup provides structured, real-time web access purpose-built for AI systems. Together, they give you the flexibility of open-source with the data freshness production applications require, without the infrastructure overhead.
Why Baseten
Baseten is a serverless inference platform for deploying open-source models in production. Use the latest open-weight models like GLM-5, Kimi K2.5, MiniMax 2.5, as a production-ready API with serverless GPU scaling.
Frontier performance - with techniques like speculative decoding and other optimizations, Baseten is able to reach 500 token per second on gpt-oss-120b and 186 tokens per second on GLM-5
Serverless & scalable - pay per minute, scale to zero or to thousands of replicas
Multi-cloud resilience - Multi-cloud Capacity Management (MCM) unifies thousands of GPUs across 10+ cloud providers for high availability and active-active deployments
Near-zero cold starts - the Baseten Delivery Network (BDN) deduplicates and caches model weights across nodes and clusters, dramatically cutting spin-up time
Enterprise-ready — SOC 2 Type II, HIPAA-compliant, custom SLAs
Why Linkup
Linkup is a search API built for AI. Linkup returns structured, source-backed content optimized for LLM consumption.
Multiple search depths - Standard for simple facts, Deep for multi-step research, and Deep Research (beta) for comprehensive reports
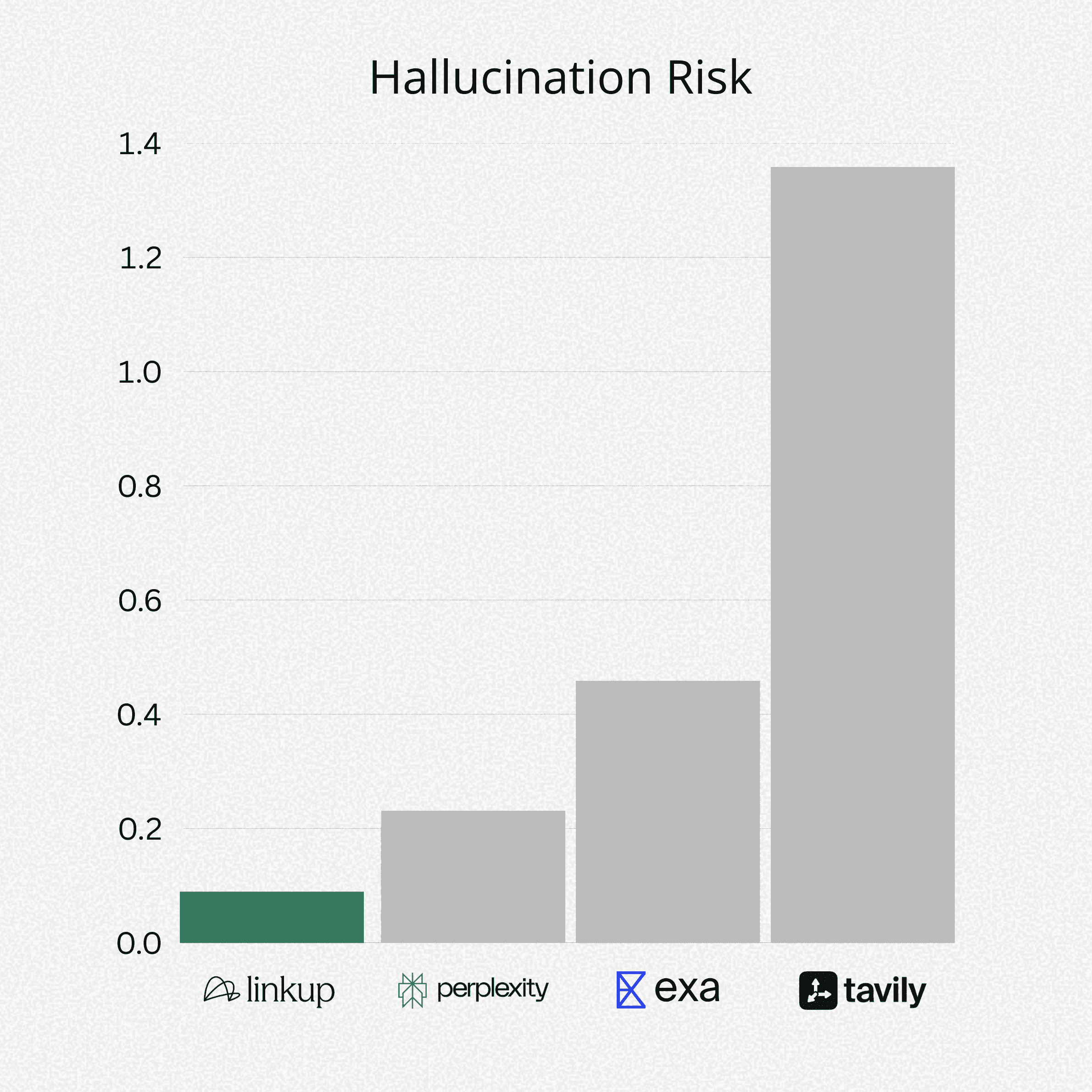
Linkup Fast - our fastest endpoint, purpose-built for latency-sensitive agents; world’s most accurate sub-second web search, as measured by F1-score on Verified SimpleQA.
Source attribution - every result includes URLs and snippets for grounding
Privacy-first - zero data retention, SOC 2 Type II compliant
Since launching in late 2024, Linkup has served tens of thousands of customers - from AI-native startups like Artisan AI and Legora, to global enterprises like KPMG and Arab Bank.
How It Works Together
In two steps, you can integrate any open-source model with live web search: check out our tutorial.
Select a model on Baseten
Define a search_web tool powered by Linkup
The model determines when it needs live information. When it does, Linkup handles the retrieval:
User → "What are the latest books on logic?"
↓
GLM-5 (Baseten) → calls search_web
↓
Linkup API → returns structured results from the live web
↓
GLM-5 → synthesizes a grounded, cited answer
The model handles reasoning. Linkup handles retrieval. Baseten handles infrastructure. Each does what it's best at.
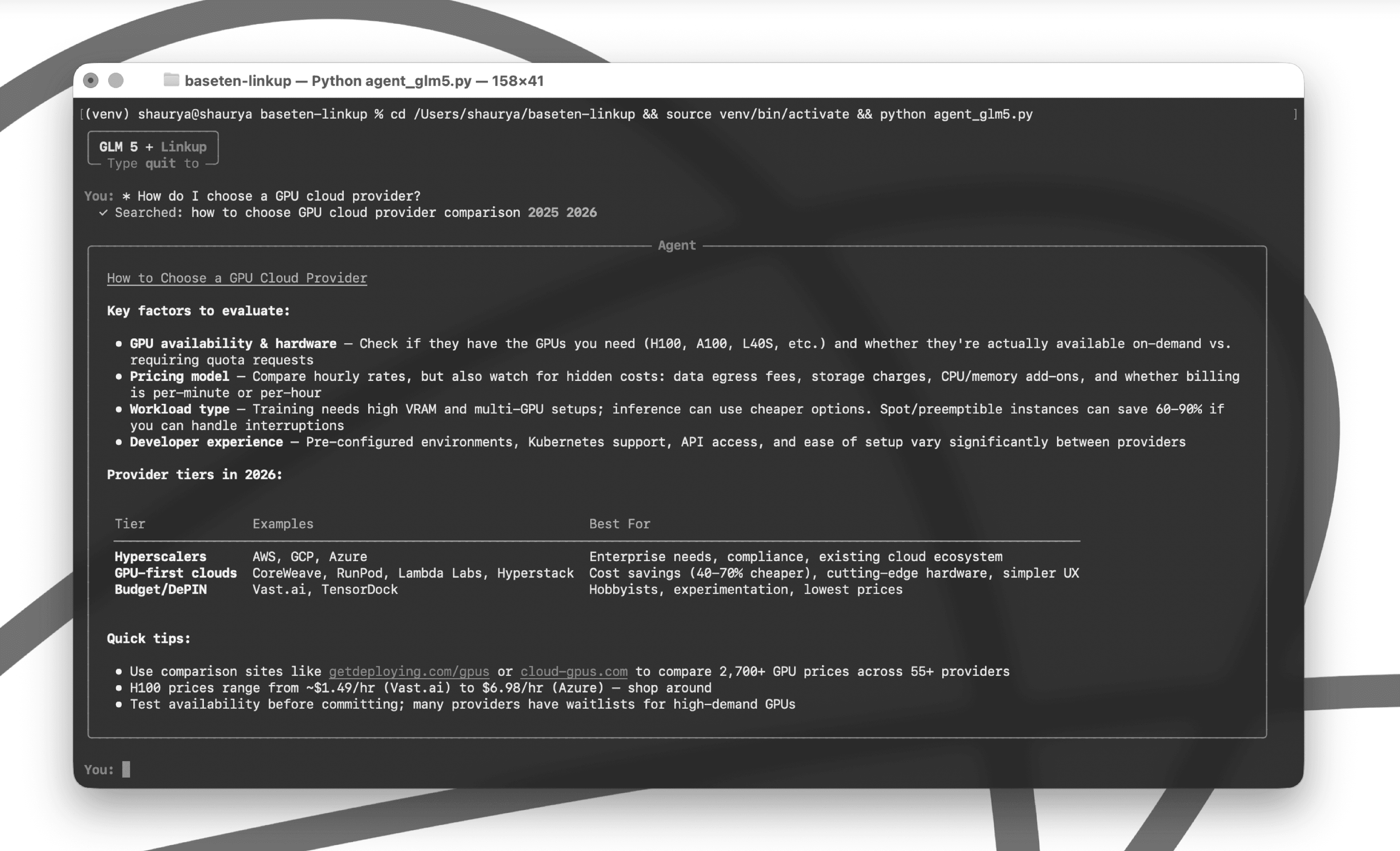
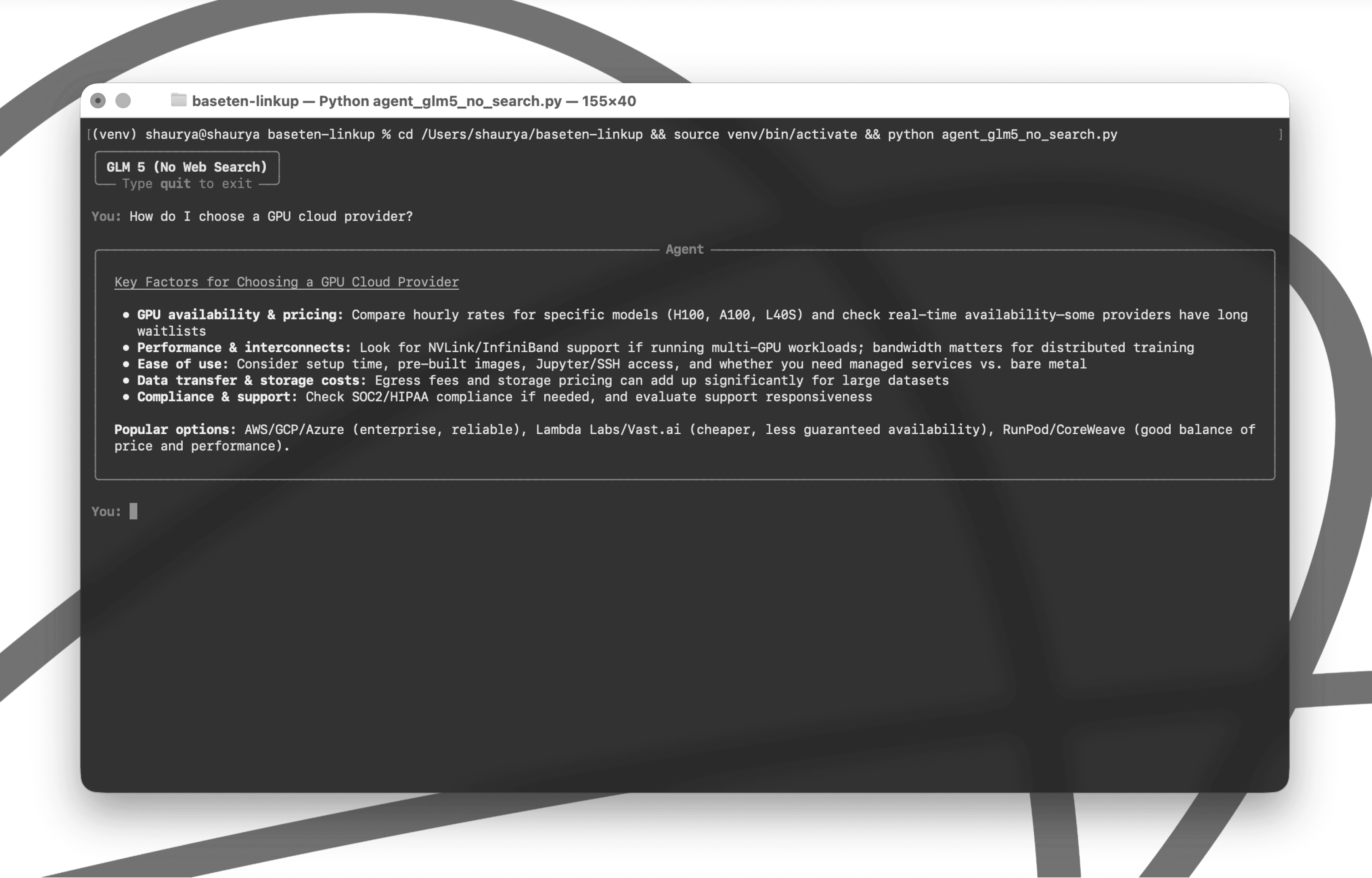
See the difference in practice
Same model. Same question. Opposite results.
Without web access, GLM 5 falls back on stale training data - generic advice with no real-world pricing, no provider comparisons, and no way to verify what's current.
With Linkup plugged in, the model searches the live web before answering. The result is grounded, specific, and current - pulling actual H100 pricing ranges, tiered provider comparisons, and links to live GPU comparison tools.