
Web RAG: From 6 Fragile Calls to 1 Reliable Endpoint
Boris Toledano
COO & Co-founder
Modern internet retrieval‑augmented generation (RAG) stacks often resemble a Rube Goldberg machine: half a dozen APIs stitched together just to turn a plain‑language question into an answer. Every extra hop adds dollars, seconds, and operational headache. What if you could collapse that entire chain into a single endpoint?
(TL;DR – one POST /search to Linkup is ≈ 30× cheaper and ≈ 4× faster than the classic “roll‑your‑own” pipeline, while also delivering SOTA 91 % F‑score on SimpleQA)
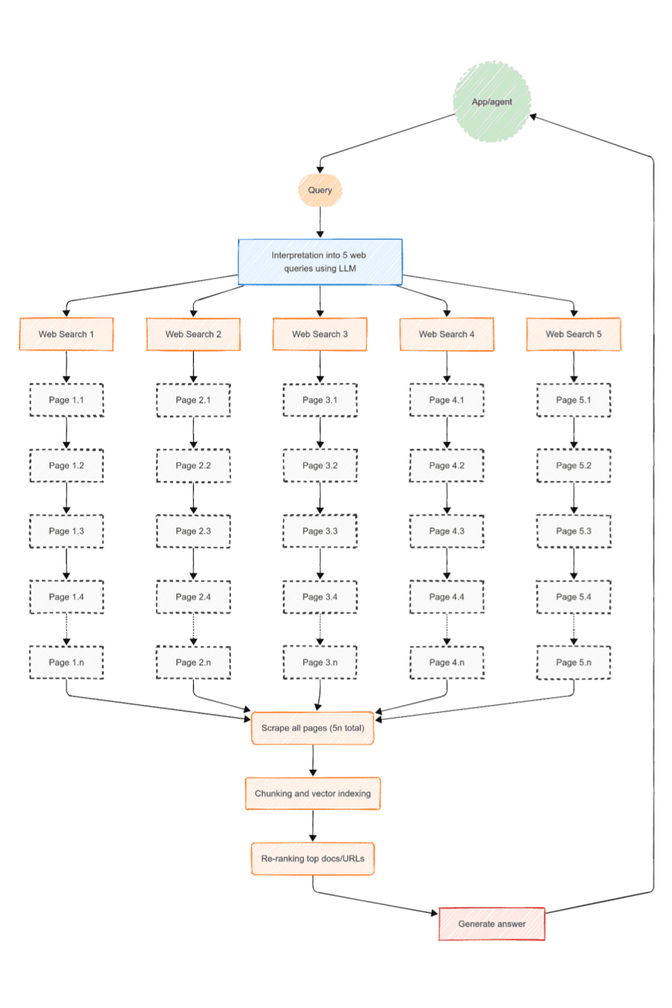
A home‑rolled web‑RAG flow typically runs through six distinct stages: craft multiple search queries with an LLM (e.g. 5), call a SERP API for each, scrape every resulting page (let's say the top 10 for each query, so 50 pages), chunk the text into embeddings, rerank the passages, and finally prompt another LLM with the distilled context. Let’s add up the latency and financial costs of these different steps.
1 — The classic pipeline (pain included)
Stage | Typical provider | Calls per user prompt | Unit cost | Latency (p50) | |
1. Prompt → 5 web queries | GPT‑4.1 | 1 | $2.00 / 1M tokens | ≈ 1 s | |
2. Web search | SerpApi | 5 | $0.015 / query | ≈ 2.3 s each can be done in parallel) | |
3. Page scraping (50 URLs) | Bright Data | 25 | $0.001 / page | ≈ 1.0 s each (can be done in parallel) | |
4. Chunking & vector index | self‑host | 1 | infra / DevOps | ~negligible but blocking | |
5. Re‑ranking top docs | Cohere Rerank 2 | 1 | $0.05 | ≈ 1.5 s | |
6. Answer generation | GPT‑4.1 | 1 | $12.00 / 1M tokens | ≈ 2 s |
End‑to‑end (sequential)
• Cost: ~ $150 for 1000 prompts
• Latency: ~ 8 s
• Failure modes: quota limits, captchas, parser drift, cascading timeouts.
As the table makes painfully clear, doing retrieval the hard way stacks costs and latency faster than you can say “timeout error.” What you really want is a single service that takes your question, handles every intermediate step- query generation, web search, scraping, chunking, re‑ranking and hands back ready‑to‑use context (or even the final answer) in one shot.
Enters Linkup.
2 — The Linkup shortcut
What is Linkup? Think of it as a single‑endpoint, web‑grounded Q&A engine: you send a plain‑language question and it quietly handles the querying, crawling, chunking, re‑ranking and answer synthesis—no proxies, captchas or vector DB babysitting required.
Now, let’s see how Linkup compares to the DIY route.
Setting | Unit cost | p50 latency | What you get | |
standard | €0.005 | ~2s | direct answer + sources |
End‑to‑end
• Cost: $5 for 1000 prompts
• Latency: ~2 s
• One moving part: Linkup handles query generation, search, crawling, de‑dup, chunking, re‑ranking and returns ready‑to‑use context (or even the final answer).

Linkup offers a much simpler approach, with 1 service instead of 6. The performance is also significantly better. Let’s compare the two options:
3 — Cost & latency delta at a glance
Metric | Legacy stack | Linkup (standard) | Δ improvement | |
Direct API costs | $0.15 | $0.005 | ‑97 % (≈ 30× cheaper) | |
Wall‑clock latency | ~8 s | ~2 s | ‑75 % (≈ 4× faster) | |
Failure surface | 6 vendors | 1 vendor | fewer retries, simpler observability |
4 — Quality doesn’t suffer (it improves)
Linkup recently topped the SimpleQA leaderboard with a 91 % F‑score, outperforming every other web‑connected system. In other words, you pay less, wait less, and get better factual recall. This is due to Linkup's proprietary search algorithm, as well as its access to premium sources of fresh, trusted data.
5 — Take‑aways
- DevEx: < 5 mins to swap in the Linkup SDK from your current pipeline.
- Performance: State-of-the-artswer quality (91% on SimpleQA) and 4x faster latency.
- OpEx: ~ $5 vs. ~$150 for 1000 real-time searches with Linkup vs. DIY stack.
- Peace of mind: one SLA, one bill, fewer 3 am alerts.
Bottom line: if your product still strings together LLM → SERP → scraper → rerank, you’re burning money and user patience. One Linkup call now beats the whole stack on both accuracy and efficiency—no tuning required.
Sources
- OpenAI- https://openai.com/api/pricing/
- SerpApi- https://serpapi.com/pricing
- Bright Data- https://brightdata.com/pricing/web-scraper
- Cohere Rerank- https://cohere.com/pricing


